
What is NoSQL and Benefits of Using it for App Development

During the early ages of computers as storage of information became a problem, the concept of ‘databases’ was introduced where all the information could be stored so that it was possible to retrieve information as and when required across sessions. It was stored in numbered or coded format as well as in singular tables. As the data stored increased, it obviously became complex and thereby difficult to maintain. This led to the innovation of relational databases which solved most of these problems.
However in this age even the database relations are updated far too often. The increase in number of users as well as the complexity of information required to be saved every now and then has resulted in very complex databases which are required to update regularly thousands and millions of requests every moment. The cost of handling and maintaining databases has increased ridiculously.
And now has come ‘noSQL’ databases. It is becoming popular by the day which is why I decided to write this blog. So let’s explore the curious case of this new database model and learn what exactly is this?
What is NoSQL?
NoSQL systems are also called “Not only SQL” to emphasize that they may also support SQL-like query languages.
NoSQL encompasses a wide variety of different database technologies and was developed in response to a
- rise in the volume of data stored about users, objects and products,
- the frequency in which this data is accessed,
- performance and
- processing needs.
Relational databases on the other hand, were not designed to cope with the scale and agility challenges which challenge modern applications, nor were they built to take advantage of the cheap storage and processing power available today.
NoSQL Database Types
Document databases pair each key with a complex data structure known as a document. Documents can contain many different key-value pairs, or key-array pairs, or even nested documents.
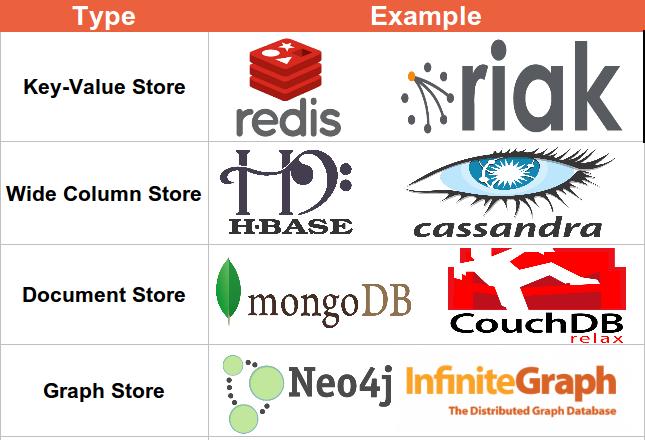
Graph stores are used to store information about networks, such as social connections. Graph stores include Neo4J and HyperGraphDB.
Key-value stores are the simplest NoSQL databases. Every single item in the database is stored as an attribute name (or “key”), together with its value. Examples of key-value stores are Riak and Voldemort. Some key-value stores, such as Redis, allow each value to have a type, such as “integer”, which adds functionality.
Wide-column stores such as Cassandra and HBase are optimized for queries over large datasets, and store columns of data together, instead of rows.
The Benefits of NoSQL
When compared to relational databases, NoSQL databases are more scalable and provide superior performance, and their data model addresses several issues that the relational model is not designed to address:
- Large volumes of structured, semi-structured, and unstructured data
- Agile sprints, quick iteration, and frequent code pushes
- Object-oriented programming that is easy to use and flexible
- Efficient, scale-out architecture instead of expensive, monolithic architecture
- Dynamic Schemas
Relational databases require that schemas be defined before you can add data. For example, you might want to store data about your customers such as phone numbers, first and last name, address, city and state – a SQL database needs to know what you are storing in advance.
This fits poorly with agile development approaches, because each time you complete new features, the schema of your database often needs to change. So if you decide after a few iterations into development that you’d like to store customers’ favorite items in addition to their addresses and phone numbers, you’ll need to add that column to the database, and then migrate the entire database to the new schema.
If the database is large, this is a very slow process that involves significant downtime. If you are frequently changing the data your application stores – because you are iterating rapidly – this downtime may also be frequent. There’s also no way, using a relational database, to effectively address data that’s completely unstructured or unknown in advance.
NoSQL databases are built to allow the insertion of data without a predefined schema. That makes it easy to make significant application changes in real-time, without worrying about service interruptions – which means development is faster, code integration is more reliable, and less database administrator time is needed.
Auto-sharding
Because of the way they are structured, relational databases usually scale vertically – a single server has to host the entire database to ensure reliability and continuous availability of data. This gets expensive quickly, places limits on scale, and creates a relatively small number of failure points for database infrastructure. The solution is to scale horizontally, by adding servers instead of concentrating more capacity in a single server.
“Sharding” a database across many server instances can be achieved with SQL databases, but usually is accomplished through SANs and other complex arrangements for making hardware act as a single server. Because the database does not provide this ability natively, development teams take on the work of deploying multiple relational databases across a number of machines. Data is stored in each database instance autonomously. Application code is developed to distribute the data, distribute queries, and aggregate the results of data across all of the database instances. Additional code must be developed to handle resource failures, to perform joins across the different databases, for data rebalancing, replication, and other requirements. Furthermore, many benefits of the relational database, such as transactional integrity, are compromised or eliminated when employing manual sharding.
NoSQL databases, on the other hand, usually support auto-sharding, meaning that they natively and automatically spread data across an arbitrary number of servers, without requiring the application to even be aware of the composition of the server pool. Data and query load are automatically balanced across servers, and when a server goes down, it can be quickly and transparently replaced with no application disruption.
Cloud computing makes this significantly easier, with providers such as Amazon Web Services providing virtually unlimited capacity on demand, and taking care of all the necessary database administration tasks. Developers no longer need to construct complex, expensive platforms to support their applications, and can concentrate on writing application code. Commodity servers can provide the same processing and storage capabilities as a single high-end server for a fraction of the price.
Replication
Most NoSQL databases also support automatic replication, meaning that you get high availability and disaster recovery without involving separate applications to manage these tasks. The storage environment is essentially virtualized from the developer’s perspective.
Integrated Caching
A number of products provide a caching tier for SQL database systems. These systems can improve read performance substantially, but they do not improve write performance, and they add complexity to system deployments. If your application is dominated by reads then a distributed cache should probably be considered, but if your application is dominated by writes or if you have a relatively even mix of reads and writes, then a distributed cache may not improve the overall experience of your end users.
Many NoSQL database technologies have excellent integrated caching capabilities, keeping frequently-used data in system memory as much as possible and removing the need for a separate caching layer that must be maintained.
Implementing a NoSQL Database in Your Organization
Often, organizations will begin with a small-scale trial of a NoSQL database in their organization, which makes it possible to develop an understanding of the technology in a low-stakes way. Most NoSQL databases are also open-source, meaning that they can be downloaded, implemented and scaled at little cost. Because development cycles are faster, organizations can also innovate more quickly and deliver superior customer experience at a lower cost.
Selecting the right NoSQL database for your application and goals is important. We can provide the guidance you need at all stages of evaluation.
As you consider alternatives to legacy infrastructures, you may have several motivations: to scale or perform beyond the capabilities of your existing system, identify viable alternatives to expensive proprietary software, or increase the speed and agility of development.


