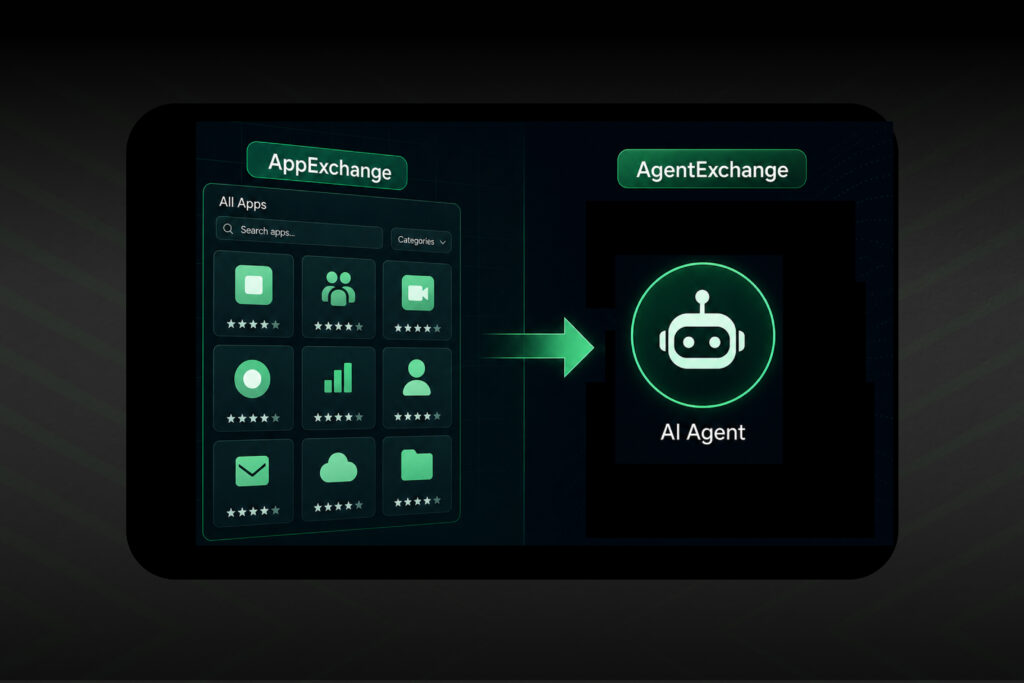
Most Agentforce deployments fail quietly. Not because the technology doesn't work, but because organizations treat it like any other Salesforce implementation. Configure, test, launch. That approach ignores what makes Agentforce different from standard Salesforce automation. Understanding Salesforce Agentforce is the starting point for closing that gap. According to Salesforce's 2025 Connectivity Benchmark Report, 93%…